

图编译优化与 Fusion Pass 融合算子接入实践
这篇帖子将从图编译的基础概念入手,落到 vLLM Ascend 中的 Fusion Pass、图匹配和图替换机制,目标是理解一条融合规则从“被定义出来”到“真正改写 FX 图”的完整过程。
此外,帖中会给出将融合算子 AddRmsNormDynamicMxQuant 接入 vllm-ascend,替换掉原有小算子 AddRmsNorm + DynamicMxQuant 的实践例子。新的融合算子接入后,实测算子层面融合前后 AvgTime 从 7.541us 降低到了 3.525us。
一、链路全景图
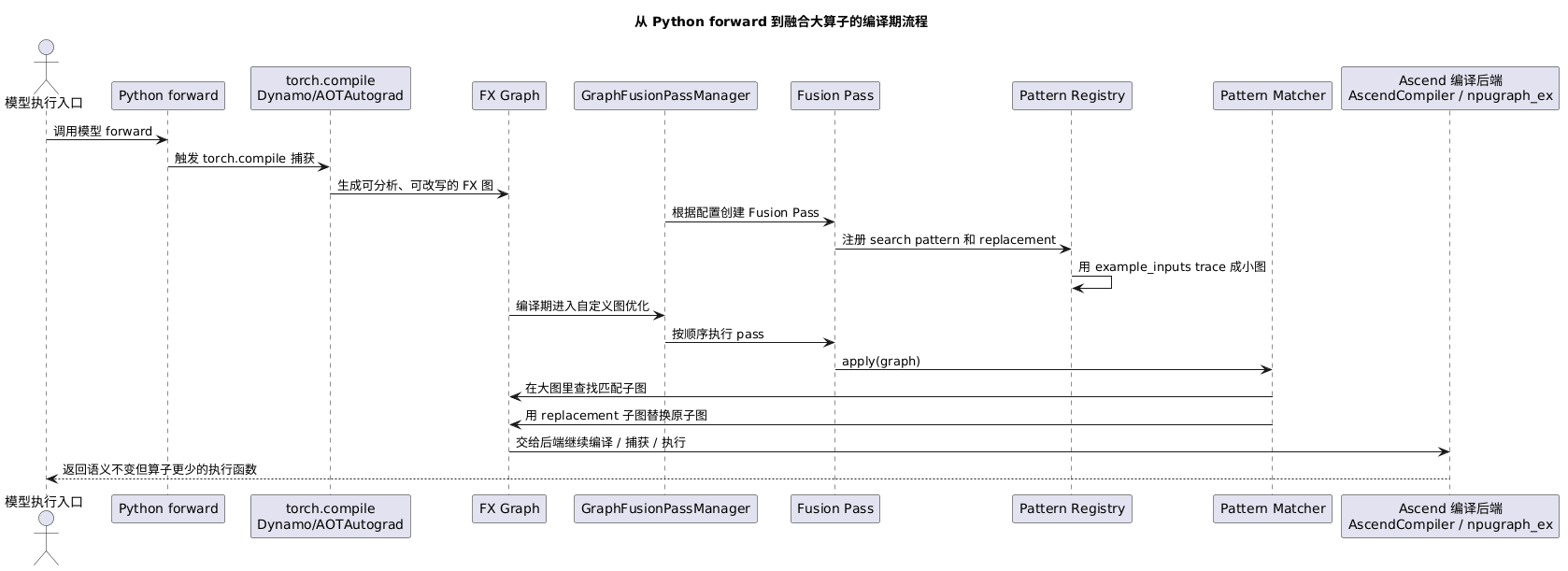
@startuml
title 从 Python forward 到融合大算子的编译期流程
actor "模型执行入口" as user
participant "Python forward" as py
participant "torch.compile\nDynamo/AOTAutograd" as dynamo
participant "FX Graph" as fx
participant "GraphFusionPassManager" as manager
participant "Fusion Pass" as pass
participant "Pattern Registry" as registry
participant "Pattern Matcher" as matcher
participant "Ascend 编译后端\nAscendCompiler / npugraph_ex" as backend
user -> py: 调用模型 forward
py -> dynamo: 触发 torch.compile 捕获
dynamo -> fx: 生成可分析、可改写的 FX 图
manager -> pass: 根据配置创建 Fusion Pass
pass -> registry: 注册 search pattern 和 replacement
registry -> registry: 用 example_inputs trace 成小图
fx -> manager: 编译期进入自定义图优化
manager -> pass: 按顺序执行 pass
pass -> matcher: apply(graph)
matcher -> fx: 在大图里查找匹配子图
matcher -> fx: 用 replacement 子图替换原子图
fx -> backend: 交给后端继续编译 / 捕获 / 执行
backend --> user: 返回语义不变但算子更少的执行函数
@enduml
整条链路可以拆成三句话:
- 图编译:把普通 Python forward 捕获成一张可分析、可修改的 FX 图。
- 图匹配:把预先注册的小图模式拿到真实 FX 图里查找同构子图。
- 图替换:命中后,用语义等价但更高效的融合算子子图替换原子图。
这套机制发生在编译期,不是在模型 Python 源码里临时改某一行。运行时看到的还是同一个 forward 语义,但底层执行图已经被改写。
二、基础概念
2.1 FX 图是什么
PyTorch FX 可以把一段 Python 计算表示成“图”。图里的每个节点代表一件明确的事,例如输入占位符、调用某个算子、取 tuple 的某个输出、返回结果。
一个普通 Python 片段:
y = op1(x)
z = op2(y)
return z
在 FX 图中可以近似理解成:
placeholder[x]
│
▼
call_function[op1]
│
▼
call_function[op2]
│
▼
output
FX 图的关键价值是:它把“代码执行过程”变成了“数据依赖图”。编译器可以遍历节点、检查某个节点的输入输出、替换一段子图,然后重新生成可执行代码。
在本文关注的融合场景里,真实图大致长这样:
%norm = call_function[target=torch.ops.npu.npu_add_rms_norm](...)
%norm_0 = call_function[target=operator.getitem](%norm, 0)
%norm_2 = call_function[target=operator.getitem](%norm, 2)
%mx = call_function[target=torch.ops.npu.npu_dynamic_mx_quant](%norm_0, ...)
%q = call_function[target=operator.getitem](%mx, 0)
%scale = call_function[target=operator.getitem](%mx, 1)
return (%q, %scale, %norm_2)
其中 operator.getitem 很常见,因为很多 NPU 算子会返回 tuple。FX 图不会把 output[0] 当作注释,而是会显式记录“从某个多输出节点取第 0 个输出”。
2.2 图编译是什么
图编译可以理解为:
Python 代码
-> 捕获成 FX 图
-> 做图优化
-> 交给硬件后端生成更适合执行的形式
对于推理系统,图编译的重要收益有两类:
- 减少 Python 调度开销:执行已经捕获好的图,而不是每一步都回到 Python。
- 做算子级优化:识别常见算子组合,把多个小算子替换成一个融合大算子,减少内存读写和调度开销。
本文的 norm + dynamic MX quant fusion 属于第二类。
2.3 Fusion Pass 是什么
Fusion Pass 是一段“图优化逻辑”。它接收一张 FX 图,检查图里是否存在某些可优化模式,并在满足条件时改写图。
可以把 Fusion Pass 想成一个编译期编辑器:
输入:一张 FX 图
工作:查找 A -> B -> C 这种特定结构
输出:把它改成 FusedABC,同时保持对外语义不变
一个 Pass 通常包含三部分:
Pattern 旧子图长什么样
Replacement 新子图长什么样
Guard 什么条件下允许替换
其中 Guard 可以包括 dtype、硬件型号、算子符号是否存在、shape 是否符合、节点是否在同一 stream 等。
2.4 Pattern 和 Replacement 是什么
在 vLLM Ascend 当前实现中,Pattern 和 Replacement 都用 Python 函数描述。
pattern_fn 描述“要找的旧计算”
replacement_fn 描述“替换后的新计算”
example_inputs 给 tracer 一组样例输入,让它把两个函数 trace 成小 FX 图
Pattern matcher 不靠字符串搜索,也不靠源码行号,而是比较图结构。简化后可以理解成:
search pattern 小图:
add_rms_norm -> getitem(0) -> dynamic_mx_quant
└-------> getitem(2)
真实 FX 大图:
... -> add_rms_norm -> getitem(0) -> dynamic_mx_quant -> ...
└---------> getitem(2) ---------------------> ...
如果结构、算子 target、常量参数、输出使用关系都对得上,就命中。
三、vLLM Ascend 如何把 Pass 接入编译链路
Ascend 平台向 vLLM 暴露了自定义 pass manager 和 compiler backend。平台侧只给出类路径,真正的对象创建和调用由 vLLM 编译流程驱动。
class NPUPlatform(Platform):
...
@property
def pass_key(self) -> str:
...
return COMPILATION_PASS_KEY
@classmethod
def get_pass_manager_cls(cls) -> str:
...
return "vllm_ascend.compilation.graph_fusion_pass_manager.GraphFusionPassManager"
@classmethod
def get_compile_backend(self) -> str:
...
return "vllm_ascend.compilation.compiler_interface.AscendCompiler"
...
GraphFusionPassManager 是 Fusion Pass 的调度器。它根据配置决定启用哪些 pass,然后在编译期按顺序调用它们。
class GraphFusionPassManager:
...
def configure(self, config: VllmConfig):
from vllm_ascend.utils import is_310p
# By default, we enable the graph fusion and quantization fusion pass.
self.ascend_compilation_config: dict = config.additional_config.get("ascend_compilation_config", {})
if self.ascend_compilation_config.get("fuse_norm_quant", True) and not is_310p():
from .passes.norm_quant_fusion_pass import AddRMSNormQuantFusionPass
self.passes.append(AddRMSNormQuantFusionPass(config))
if self.ascend_compilation_config.get("fuse_qknorm_rope", True):
...
真正执行 pass 的代码很短:
class GraphFusionPassManager:
...
def __call__(self, graph: fx.Graph) -> fx.Graph:
compile_range = get_pass_context().compile_range
for pass_ in self.passes:
if pass_.is_applicable_for_range(compile_range):
pass_(graph)
graph.recompile()
return graph
这里有两个机制点:
pass_(graph)是原地改写 FX 图。graph.recompile()会让 FX GraphModule 根据修改后的图重新生成可执行代码。
四、两条编译路径:直接改 FX 图与后端注册
vLLM Ascend 里存在两条相关路径:
enable_npugraph_ex = false
-> AscendCompiler 显式调用 GraphFusionPassManager
-> PatternMatcherPass.apply(graph) 直接改写 FX 图
enable_npugraph_ex = true
-> AscendCompiler 把图交给 npugraph_ex / torchair
-> 由后端使用已注册 replacement 做图优化
直接改写路径的核心代码如下:
def fusion_pass_compile(
graph: fx.GraphModule,
example_inputs: list[Any],
compiler_config: dict[str, Any],
compile_range: Range,
key: str | None = None,
) -> tuple[Callable | None, Any | None]:
def compile_inner(graph, example_inputs):
current_pass_manager = compiler_config[COMPILATION_PASS_KEY]
graph = current_pass_manager(graph)
return graph
...
compiled_fn = compile_fx(
graph=graph,
example_inputs=example_inputs,
inner_compile=compile_inner,
decompositions=decompositions,
)
return compiled_fn, None
启用 npugraph_ex 时,AscendCompiler 不在这里显式执行 pass manager,而是把图交给后端:
class AscendCompiler(CompilerInterface):
...
def compile(
self,
graph: fx.GraphModule,
example_inputs: list[Any],
compiler_config: dict[str, Any],
compile_range: Range,
key: str | None = None,
) -> tuple[Callable | None, Any | None]:
...
ascend_compilation_config = get_ascend_config().ascend_compilation_config
if ascend_compilation_config.enable_npugraph_ex:
logger.info("enable_npugraph_ex is enabled, which will bring graph compilation optimization.")
assert hasattr(self, "vllm_config")
return npugraph_ex_compile(
graph, example_inputs, compiler_config, self.vllm_config, ascend_compilation_config, compile_range, key
)
else:
return fusion_pass_compile(graph, example_inputs, compiler_config, compile_range, key)
因此,同一个 pattern 要同时注册到 PyTorch Inductor matcher 和 npugraph_ex/torchair 后端。这正是 BasePattern.register() 同时调用两套 API 的原因。
五、BasePattern:把 Python 函数变成图匹配规则
每个具体融合模式都继承 BasePattern,并实现三个方法:
get_inputs() 产生样例输入,用于 trace pattern/replacement
get_pattern() 返回 search 函数,描述旧子图
get_replacement() 返回 replace 函数,描述新子图
注册逻辑如下:
class BasePattern(ABC):
...
def register(self, pm_pass: PatternMatcherPass) -> None:
# Create a unique identifier for this pattern based on class name and eps
pattern_id = f"{self.__class__.__name__}_{self.eps}"
# Skip registration if this pattern has already been registered globally
if pattern_id in _registered_patterns:
return
pattern_fn = self.get_pattern()
replacement_fn = self.get_replacement()
example_inputs = self.get_inputs()
pm.register_replacement(pattern_fn, replacement_fn, example_inputs, pm.fwd_only, pm_pass)
nge.register_replacement(
search_fn=pattern_fn,
replace_fn=replacement_fn,
example_inputs=example_inputs,
extra_check=self.get_extra_stream_scope_check(),
)
# Mark this pattern as registered
_registered_patterns.add(pattern_id)
这段代码完成了四件事:
- 生成
pattern_id,避免同一个 pattern 在进程内重复注册。 - 拿到旧子图函数、新子图函数和样例输入。
- 调用
pm.register_replacement(...),注册给 PyTorch Inductor pattern matcher。 - 调用
nge.register_replacement(...),注册给 npugraph_ex/torchair 后端。
其中 example_inputs 不是为了跑真实推理,而是为了让注册系统能 trace 出“小图”:
pattern_fn(example_inputs) -> search graph
replacement_fn(example_inputs) -> replacement graph
后续匹配真实 FX 图时,系统用 search graph 找结构;命中后,再用 replacement graph 生成替换节点。
六、图匹配到底在匹配什么
Pattern matcher 本质上是在做子图匹配:
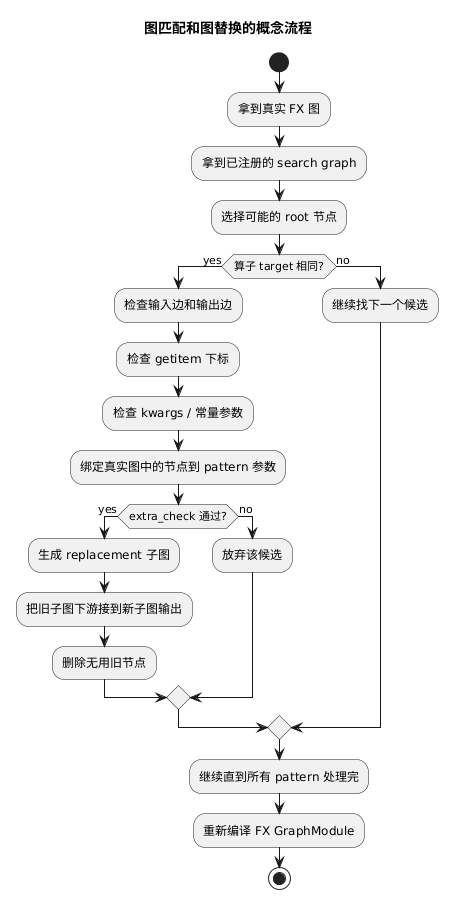
@startuml
title 图匹配和图替换的概念流程
start
:拿到真实 FX 图;
:拿到已注册的 search graph;
:选择可能的 root 节点;
if (算子 target 相同?) then (yes)
:检查输入边和输出边;
:检查 getitem 下标;
:检查 kwargs / 常量参数;
:绑定真实图中的节点到 pattern 参数;
if (extra_check 通过?) then (yes)
:生成 replacement 子图;
:把旧子图下游接到新子图输出;
:删除无用旧节点;
else (no)
:放弃该候选;
endif
else (no)
:继续找下一个候选;
endif
:继续直到所有 pattern 处理完;
:重新编译 FX GraphModule;
stop
@enduml
匹配的不是“两个函数名字是否一样”这么简单,而是综合比较:
节点类型 call_function / placeholder / output
算子 target torch.ops.npu.npu_add_rms_norm 等
数据依赖 某个输出是否流向某个输入
tuple 输出 getitem 取的是第几个输出
常量参数 eps、dst_type 等是否一致
额外 guard stream、shape、硬件能力等是否允许融合
多输出算子是这类融合中的重点。以 npu_add_rms_norm 为例,旧图会把同一个算子结果拆成多个输出继续使用:
┌─ getitem(0) -> normalized -> dynamic_mx_quant
npu_add_rms_norm ┤
└─ getitem(2) -> residual_out
如果 replacement 的融合算子输出顺序不同,也没有关系。只要 replacement 最终返回的语义顺序和旧子图一致即可。
七、图替换如何保持语义不变
图替换的目标不是看到两个 op 就无脑换掉,而是要确保输入输出语义不变。
旧子图对外暴露三个结果:
quantized_output, mxscale, new_residual
融合算子内部可能用不同顺序返回:
output[0] = quantized_output
output[1] = new_residual
output[2] = mxscale
replacement 需要把它重新排列回旧语义:
return (
output[0], # quantized_output
output[2], # mxscale
output[1], # new_residual
)
这也是 replacement 函数的核心价值:它不只是换一个算子名,还负责把新算子的输入、输出、属性组织成与旧子图等价的结构。
八、Guard:为什么不能所有图都融合
融合必须满足运行时和语义条件。vllm-ascend 当中,目前 norm + quant pass 主要有几类 guard。
第一类是 dtype guard。AddRMSNormQuantFusionPass 只在 bfloat16 和 float16 下注册:
class AddRMSNormQuantFusionPass(VllmInductorPass):
...
def __init__(self, vllm_config: VllmConfig):
super().__init__(vllm_config)
self.pattern_match_passes: PatternMatcherPass = PatternMatcherPass(pass_name="rmsnorm_quant_fusion_pass")
dtype = vllm_config.model_config.dtype
if dtype not in (torch.bfloat16, torch.float16):
logger.debug("Quant fusion not enabled: unsupported dtype %s", dtype)
return
common_epsilons = [1e-5, 1e-6]
dynamic_mx_quant_fusion_available = is_add_rms_norm_dynamic_mx_quant_fusion_available()
...
第二类是 runtime symbol 和硬件能力 guard。dynamic MX 融合只有在当前设备和 torch_npu 运行时都支持对应符号时才注册:
def _is_dynamic_mx_quant_fusion_soc_supported() -> bool:
return get_ascend_device_type() == AscendDeviceType.A5
def is_add_rms_norm_dynamic_mx_quant_fusion_available() -> bool:
return _is_dynamic_mx_quant_fusion_soc_supported() and hasattr(torch, "float8_e4m3fn") and not _get_missing_symbols(
("npu_dynamic_mx_quant", "npu_add_rms_norm_dynamic_mx_quant")
)
第三类是 stream guard。BasePattern 注册给 npugraph_ex/torchair 时带了 extra_check,默认检查匹配到的节点是否处在同一个 stream 范围内:
def extra_stream_scope_check(match: Match) -> bool:
"""
Checks if all nodes in the same stream.
"""
non_default_streams = set()
has_default = False
for node in match.nodes:
if node.op == "call_function":
current_stream = node.meta.get("stream_label")
if current_stream is None:
has_default = True
else:
non_default_streams.add(current_stream)
if len(non_default_streams) > 1:
...
return False
if has_default and len(non_default_streams) > 0:
...
return True
这个 guard 防止把原本跨 stream 的多段计算压成一个算子,避免改变调度语义。
九、Fusion Pass 如何真正执行替换
注册发生在 pass 初始化阶段;替换发生在 pass 被调用阶段。
class AddRMSNormQuantFusionPass(VllmInductorPass):
...
def __call__(self, graph: torch.fx.Graph):
self.begin()
self.matched_count = self.pattern_match_passes.apply(graph)
logger.debug("Replaced %s patterns", self.matched_count)
self.end_and_log()
self.pattern_match_passes.apply(graph) 会遍历当前 FX 图,把之前注册进 PatternMatcherPass 的规则逐个应用。返回值 matched_count 表示这次 pass 替换了多少个匹配。
用 ASCII 图总结就是:
注册期:
Pattern 类
-> get_pattern()
-> get_replacement()
-> get_inputs()
-> register_replacement()
编译期:
FX Graph
-> pass(graph)
-> pattern_match_passes.apply(graph)
-> graph 被原地改写
-> graph.recompile()
十、实战例子:无 Bias AddRMSNorm + DynamicMXQuant 融合
本节只看一个最小且完整的例子:无 Bias 的 AddRMSNorm + DynamicMXQuant。
10.1 原始计算
模型 forward 中的计算逻辑可以简化为:
def forward(self, x):
residual = torch.zeros_like(x)
norm_output, _, new_residual = torch.ops.npu.npu_add_rms_norm(
x, residual, self.rms_norm_weight, self.eps
)
quantized_output, mxscale = torch.ops.npu.npu_dynamic_mx_quant(
norm_output, dst_type=torch.float8_e4m3fn
)
return quantized_output, mxscale, new_residual
对应的数据流是:
x ───────┐
├─ (npu_add_rms_norm) ── output[0] ── (npu_dynamic_mx_quant) ── quantized_output
│ │ └─ mxscale
residual─│ └─ output[2] ──────────────────────────── new_residual
weight ──┘
10.2 Pattern 定义
这个旧子图由 AddRMSNormDynamicMXQuantPattern.get_pattern() 描述:
class AddRMSNormDynamicMXQuantPattern(BasePattern):
...
def get_pattern(self):
def pattern(rms_norm_input: torch.Tensor, residual: torch.Tensor, rms_norm_weight: torch.Tensor):
"""
Pattern for AddRMSNormDynamicMXQuant fusion.
"""
output = torch.ops.npu.npu_add_rms_norm(rms_norm_input, residual, rms_norm_weight, self.eps)
out0 = output[0]
out1 = output[2]
quantized_output = torch.ops.npu.npu_dynamic_mx_quant(out0, dst_type=torch.float8_e4m3fn)
return quantized_output[0], quantized_output[1], out1
return pattern
这段 pattern 明确表达了几件事:
- 第一个算子必须是
npu_add_rms_norm。 npu_add_rms_norm的output[0]必须流向npu_dynamic_mx_quant。npu_add_rms_norm的output[2]会作为旧子图第三个结果返回。npu_dynamic_mx_quant的dst_type必须是torch.float8_e4m3fn。eps来自 pattern 实例,当前 pass 注册了1e-5和1e-6两种常见值。
10.3 Replacement 定义
新子图由 get_replacement() 描述:
class AddRMSNormDynamicMXQuantPattern(BasePattern):
...
def get_replacement(self):
def replacement(rms_norm_input: torch.Tensor, residual: torch.Tensor, rms_norm_weight: torch.Tensor):
"""
Replacement for the AddRMSNormDynamicMXQuant fusion.
"""
output = torch.ops.npu.npu_add_rms_norm_dynamic_mx_quant(
rms_norm_input,
residual,
rms_norm_weight,
epsilion=self.eps,
dst_type=torch.float8_e4m3fn,
)
return (
output[0],
output[2],
output[1],
)
return replacement
融合算子一次完成 AddRMSNorm 和 DynamicMXQuant。由于融合算子的输出顺序是:
output[0] = quantized_output
output[1] = new_residual
output[2] = mxscale
而旧子图对外返回的是:
quantized_output, mxscale, new_residual
所以 replacement 返回:
output[0], output[2], output[1]
这一步保证了“图变了,语义不变”。
10.4 注册与生效
Pass 初始化时,如果 dynamic MX 融合算子可用,就注册这个 pattern:
class AddRMSNormQuantFusionPass(VllmInductorPass):
...
for eps in common_epsilons:
AddRMSNormDynamicQuantPattern(vllm_config, eps=eps).register(self.pattern_match_passes)
AddRMSNormDynamicQuantSPPattern(vllm_config, eps=eps).register(self.pattern_match_passes)
if dynamic_mx_quant_fusion_available:
AddRMSNormDynamicMXQuantPattern(vllm_config, eps=eps).register(self.pattern_match_passes)
AddRMSNormDynamicMXQuantSPPattern(vllm_config, eps=eps).register(self.pattern_match_passes)
...
编译期进入 pass 后,PatternMatcherPass.apply(graph) 会在真实 FX 图里查找与 get_pattern() trace 结果同构的子图。命中后,旧图:
%norm = npu_add_rms_norm(%x, %residual, %weight, eps)
%norm_0 = getitem(%norm, 0)
%norm_2 = getitem(%norm, 2)
%mx = npu_dynamic_mx_quant(%norm_0, dst_type=float8_e4m3fn)
%q = getitem(%mx, 0)
%scale = getitem(%mx, 1)
return (%q, %scale, %norm_2)
会被改写成:
%fused = npu_add_rms_norm_dynamic_mx_quant(
%x, %residual, %weight,
epsilion=eps,
dst_type=float8_e4m3fn
)
%q = getitem(%fused, 0)
%scale = getitem(%fused, 2)
%new_residual = getitem(%fused, 1)
return (%q, %scale, %new_residual)
十一、总结
图编译让模型 forward 从 Python 执行流变成可分析的 FX 图。Fusion Pass 在 FX 图上工作:它先注册“旧子图”和“新子图”,再在编译期做子图匹配,最后用 replacement 子图替换原子图。
AddRMSNorm + DynamicMXQuant 的融合就是这套机制的一个典型实例:
旧图:
npu_add_rms_norm
-> output[0]
-> npu_dynamic_mx_quant
新图:
npu_add_rms_norm_dynamic_mx_quant
真正保证机制可靠的,不只是“把两个算子换成一个算子”,而是完整的编译期约束:
FX 图结构要匹配
算子 target 要匹配
getitem 输出下标要匹配
eps / dst_type 等常量要匹配
runtime 符号和硬件能力要满足
replacement 返回顺序要保持旧子图语义
这些条件同时成立时,融合规则才会从一段 Python pattern 变成真实 FX 图中的算子替换。
最后值得注意的是,融合的模式可能是多种多样的,本文给出算子融合接入只是一种模式场景示例,实际可能还有带 Bias 的场景、SP 场景等,可根据实际需求分析、定义多个模式来实现尽可能高的算子替换覆盖率。
- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝