

vLLM-Ascend 低精调用路径与融合算子使能机制
一、低精外围调用链(vLLM -> vLLM-Ascend)
vLLM 推理低精的核心调用点其实就是 quant_method 的三个方法:
- create_weights:注册空 Parameter:weight / scale / offset / scale_second ...,写入 input_dim/output_dim/weight_loader 等加载元信息。
- process_weights_after_loading:权重加载阶段 checkpoint tensor 会通过 weight_loader 将 weight copy 到 create_weights 时注册的 Parameter。process_weights_after_loading 就是在权重加载之后,对权重做转置、NZ 格式转换、scale 合成、int4 pack。
- apply:实际调用
torch_npu.npu_weight_quant_batchmatmul(...),里面会做低精激活和反量化。
简化的外围调用链如图所示:
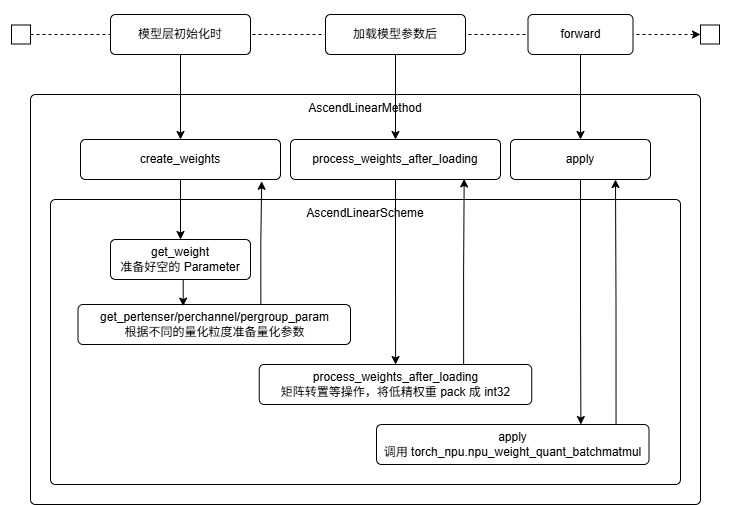
其中:
- create_weights 和 process_weights_after_loading 都是在 LLM 构造阶段完成的。
具体来说,都是 Executor
__init__时 load_model,进而调用到 GPUModelRunner 的 load_model,然后在 model_loader 里发起调用。enginecore 创建 -> executor 创建 -> worker 创建 -> runner 创建 -> 模型结构初始化 -> create_weights -> checkpoint 权重加载 -> process_weights_after_loading
- appy 是模型 forward 时级联各 layer 的 forward,进而调用到 quant_method.apply。
这里有个代码写法上的细节。模型直接
层实例(入参),这种写法是触发了类的__call__方法调用。父类 nn.Module 实现的__call__会调用forward,进而走到子类 overwrite 的forward实现。
具体 LLM 初始化和推理过程中三个 quant_method 方法被调用到的前序调用链见下面时序图:
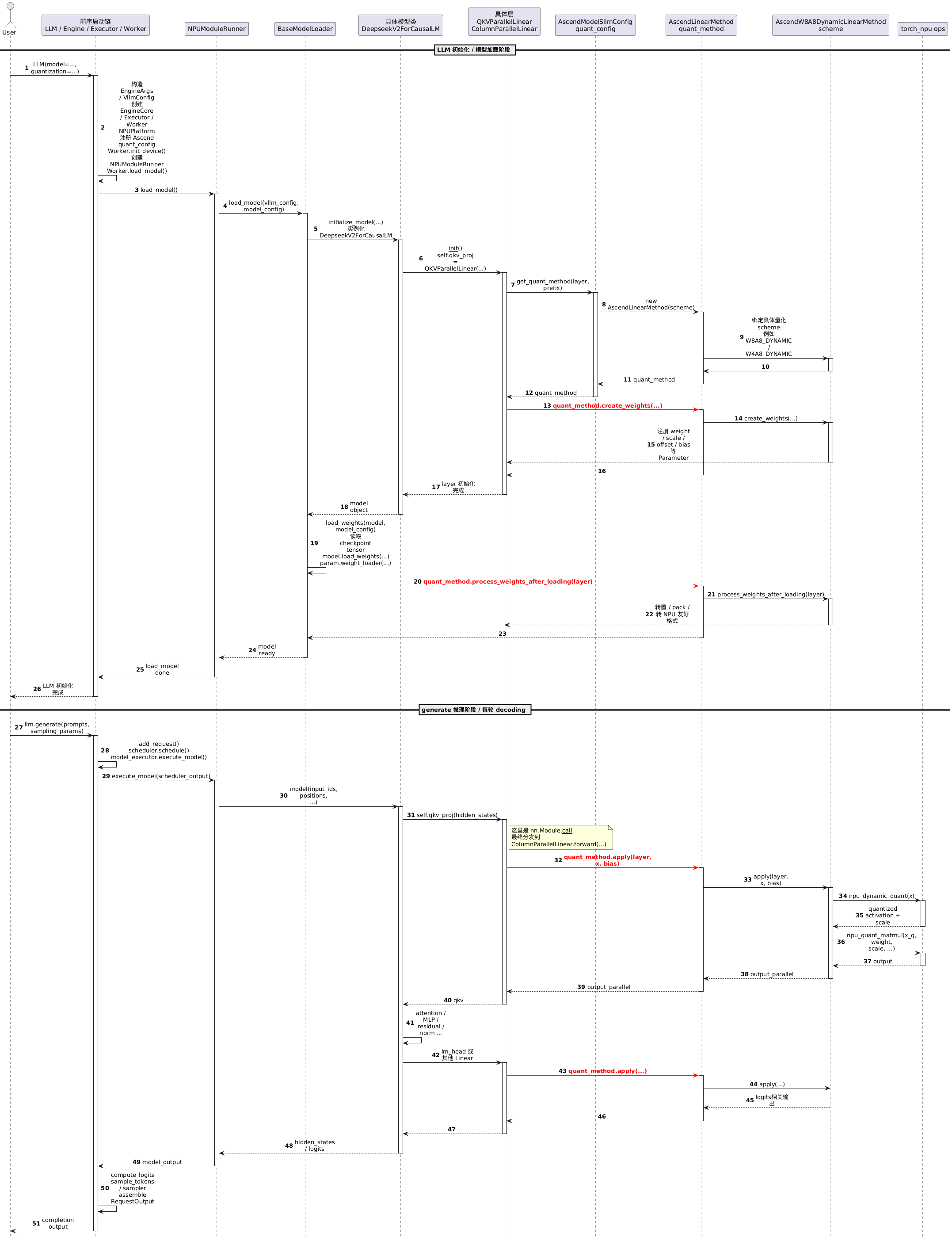
@startuml
hide footbox
autonumber
skinparam maxMessageSize 80
skinparam sequenceMessageAlign center
actor User as user
participant "前序启动链\nLLM / Engine / Executor / Worker" as pre
participant "NPUModuleRunner" as runner
participant "BaseModelLoader" as loader
participant "具体模型类\nDeepseekV2ForCausalLM" as model
participant "具体层\nQKVParallelLinear\nColumnParallelLinear" as layer
participant "AscendModelSlimConfig\nquant_config" as qconfig
participant "AscendLinearMethod\nquant_method" as qmethod
participant "AscendW8A8DynamicLinearMethod\nscheme" as scheme
participant "torch_npu ops" as npu
== LLM 初始化 / 模型加载阶段 ==
user -> pre : LLM(model=..., quantization=...)
activate pre
pre -> pre : 构造 EngineArgs / VllmConfig\n创建 EngineCore / Executor / Worker\nNPUPlatform 注册 Ascend quant_config\nWorker.init_device() 创建 NPUModuleRunner\nWorker.load_model()
pre -> runner : load_model()
activate runner
runner -> loader : load_model(vllm_config, model_config)
activate loader
loader -> model : initialize_model(...)\n实例化 DeepseekV2ForCausalLM
activate model
model -> layer : __init__()\nself.qkv_proj = QKVParallelLinear(...)
activate layer
layer -> qconfig : get_quant_method(layer, prefix)
activate qconfig
qconfig -> qmethod : new AscendLinearMethod(scheme)
activate qmethod
qmethod -> scheme : 绑定具体量化 scheme\n例如 W8A8_DYNAMIC / W4A8_DYNAMIC
activate scheme
scheme --> qmethod
deactivate scheme
qmethod --> qconfig : quant_method
deactivate qmethod
qconfig --> layer : quant_method
deactivate qconfig
layer -[#red]> qmethod : <b><color:red>quant_method.create_weights(...)</color></b>
activate qmethod
qmethod -> scheme : create_weights(...)
activate scheme
scheme --> layer : 注册 weight / scale / offset / bias 等 Parameter
deactivate scheme
qmethod --> layer
deactivate qmethod
layer --> model : layer 初始化完成
deactivate layer
model --> loader : model object
deactivate model
loader -> loader : load_weights(model, model_config)\n读取 checkpoint tensor\nmodel.load_weights(...)\nparam.weight_loader(...)
loader -[#red]> qmethod : <b><color:red>quant_method.process_weights_after_loading(layer)</color></b>
activate qmethod
qmethod -> scheme : process_weights_after_loading(layer)
activate scheme
scheme --> layer : 转置 / pack / 转 NPU 友好格式
deactivate scheme
qmethod --> loader
deactivate qmethod
loader --> runner : model ready
deactivate loader
runner --> pre : load_model done
deactivate runner
pre --> user : LLM 初始化完成
deactivate pre
== generate 推理阶段 / 每轮 decoding ==
user -> pre : llm.generate(prompts, sampling_params)
activate pre
pre -> pre : add_request()\nscheduler.schedule()\nmodel_executor.execute_model()
pre -> runner : execute_model(scheduler_output)
activate runner
runner -> model : model(input_ids, positions, ...)
activate model
model -> layer : self.qkv_proj(hidden_states)
note right of layer
这里是 nn.Module.__call__
最终分发到
ColumnParallelLinear.forward(...)
end note
activate layer
layer -[#red]> qmethod : <b><color:red>quant_method.apply(layer, x, bias)</color></b>
activate qmethod
qmethod -> scheme : apply(layer, x, bias)
activate scheme
scheme -> npu : npu_dynamic_quant(x)
activate npu
npu --> scheme : quantized activation + scale
deactivate npu
scheme -> npu : npu_quant_matmul(x_q, weight, scale, ...)
activate npu
npu --> scheme : output
deactivate npu
scheme --> qmethod : output_parallel
deactivate scheme
qmethod --> layer : output_parallel
deactivate qmethod
layer --> model : qkv
deactivate layer
model -> model : attention / MLP / residual / norm ...
model -> layer : lm_head 或其他 Linear
activate layer
layer -[#red]> qmethod : <b><color:red>quant_method.apply(...)</color></b>
activate qmethod
qmethod -> scheme : apply(...)
scheme --> qmethod : logits相关输出
qmethod --> layer
deactivate qmethod
layer --> model
deactivate layer
model --> runner : hidden_states / logits
deactivate model
runner --> pre : model_output
deactivate runner
pre -> pre : compute_logits\nsample_tokens / sampler\nassemble RequestOutput
pre --> user : completion output
deactivate pre
@enduml
二、融合算子使能
大概的流程就是:
- vllm启动过程中,
current_platform选中了NPUPlatform,VllmConfig实例化时会调用NPUPlatform的check_and_update_config,里面会替换掉worker_cls,进而后续实例化Worker时会将NPUWorker实例化出来。 - 在
NPUWorker实例化的过程中,会把 customop 注册到 vllm 的CustomOp的 oot 字典上。以RMSNorm为例。随后 vllm 加载具体的模型,比如DeepSeekV2Attention,模型构造过程中会构造各层,其中也会构造RMSNorm,进而CustomOp机制会实际实例化出AscendRMSNorm,实例化过程中会动态决定类的forward函数,根据NPUPlatform的_enum是OOT,会选到forward_oot,而AscendRMSNorm就实现了forward_oot这个函数。 - 最后,在做推理的时候,模型
forward过程中就包括AscendRMSNorm的forward_oot调用,调用时里面会调enable_custom_op,如果是首次调用的话触发import vllm_ascend.vllm_ascend_C,将各种自定义算子加载到torch.ops._C_ascend上面,然后如果结果是 True,就会调用对应自定义的_C_ascend算子,而如果对应算子是融合算子,也就是融合算子使能了,就算一条完整的融合算子使能路径了。
这里几个小点补充说明下:
- forward 不是被直接替换成
forward_oot,而是CustomOp.__init__里把_forward_method设成了forward_oot(CustomOp 是 RMSNorm 的父类);后面forward()调_forward_method()就实际调到了forward_oot。 enable_custom_op()指的不是 vLLM CustomOp,而是_C_ascend那一套 op。_C_ascend里不确定是不是都是融合算子,不过当前看到的AscendRMSNorm的npu_add_rms_norm_bias,这种看上去把 add/rmsnorm/bias 合起来的 op,应该是个融合算子(?NPUWorker构造方法里register_dummy_fusion_op()只是个占位,不是真正使能真实 kernel。
一图胜千言:
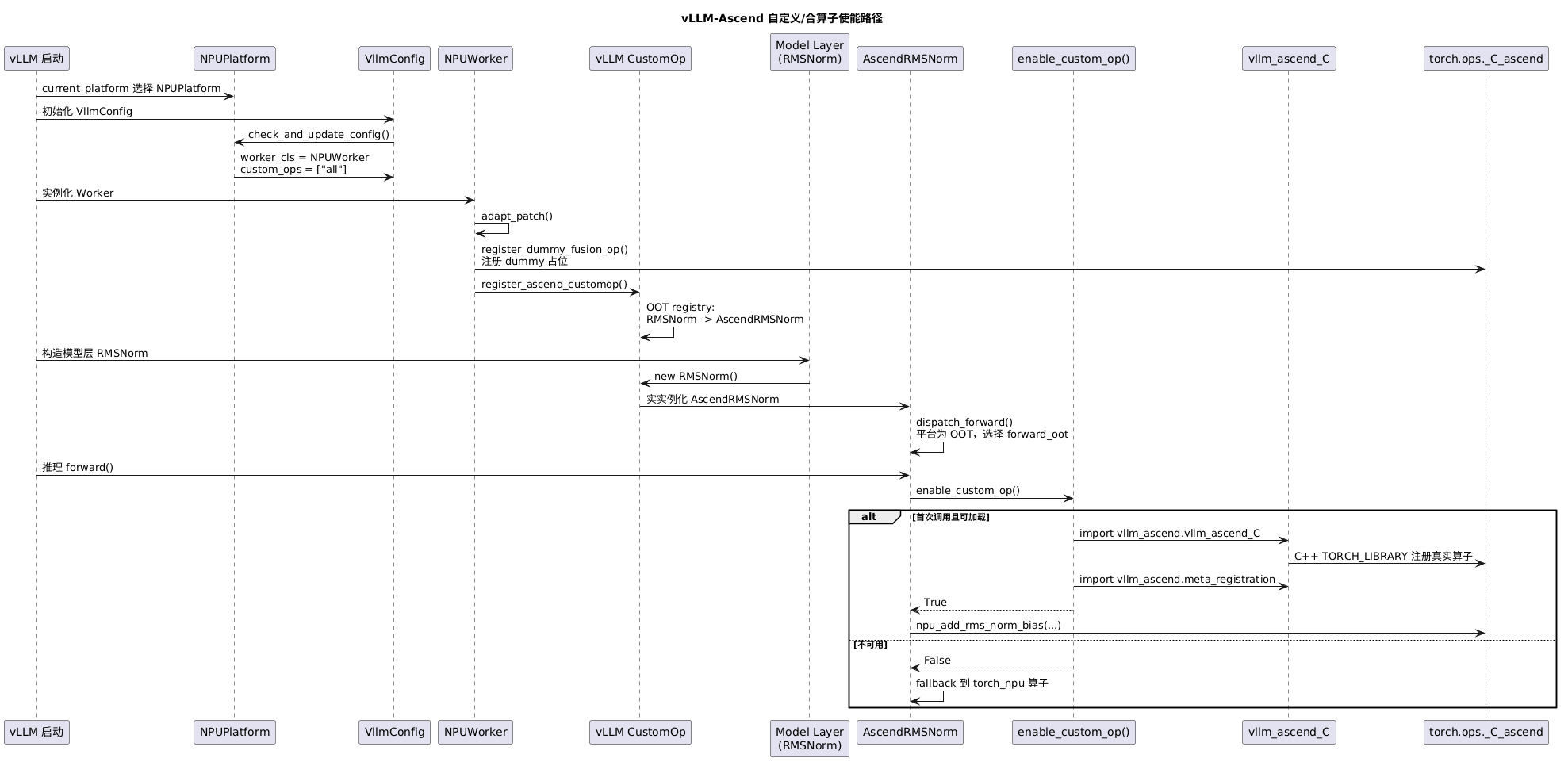
@startuml
title vLLM-Ascend 自定义/融合算子使能路径
participant "vLLM 启动" as VLLM
participant "NPUPlatform" as Platform
participant "VllmConfig" as Config
participant "NPUWorker" as Worker
participant "vLLM CustomOp" as CustomOp
participant "Model Layer\n(RMSNorm)" as Layer
participant "AscendRMSNorm" as AscendRMS
participant "enable_custom_op()" as Enable
participant "vllm_ascend_C" as Ext
participant "torch.ops._C_ascend" as Ops
VLLM -> Platform: current_platform 选择 NPUPlatform
VLLM -> Config: 初始化 VllmConfig
Config -> Platform: check_and_update_config()
Platform -> Config: worker_cls = NPUWorker\ncustom_ops = ["all"]
VLLM -> Worker: 实例化 Worker
Worker -> Worker: adapt_patch()
Worker -> Ops: register_dummy_fusion_op()\n注册 dummy 占位
Worker -> CustomOp: register_ascend_customop()
CustomOp -> CustomOp: OOT registry:\nRMSNorm -> AscendRMSNorm
VLLM -> Layer: 构造模型层 RMSNorm
Layer -> CustomOp: new RMSNorm()
CustomOp -> AscendRMS: 实际实例化 AscendRMSNorm
AscendRMS -> AscendRMS: dispatch_forward()\n平台为 OOT,选择 forward_oot
VLLM -> AscendRMS: 推理 forward()
AscendRMS -> Enable: enable_custom_op()
alt 首次调用且扩展可加载
Enable -> Ext: import vllm_ascend.vllm_ascend_C
Ext -> Ops: C++ TORCH_LIBRARY 注册真实算子
Enable -> Ext: import vllm_ascend.meta_registration
Enable --> AscendRMS: True
AscendRMS -> Ops: npu_add_rms_norm_bias(...)
else 扩展不可用
Enable --> AscendRMS: False
AscendRMS -> AscendRMS: fallback 到 torch_npu 算子
end
@enduml
简单总结:
- vLLM CustomOp OOT 机制负责把模型层替成 Ascend 实现;
- enable_custom_op 负责在 Ascend 实现内部加载并启用 _C_ascend 底层自定义算子;
- 当被调用的
_C_ascend算子本身是融合 kernel 时,就走到了融合算子路径。
三、碎碎念
看这两块的时候,单看 Method、Scheme 那块还好,后面单看 CustomOp 感觉也还好。但是回过头这两块融合在一起去感受的时候就有点迷了。从 vLLM 具体模型代码上看,以 DeepseekV2Attention 为例,它的 forward 里有如下连续的两行:
kv_a = self.kv_a_layernorm(kv_a) # 这个成员是 RMSNorm
kv = self.kv_b_proj(kv_a)[0] # 这个成员是 ColumnParallelLinear
其中上面那行是 RMSNorm,下面那行是个 LinearBase。也就是说在 forward 的视角看,RMSNorm 和 LinearBase 是平级的两个 layer,但是注入的层级和路径/机制却完全不同:
- 前者走的是 vLLM CustomOp 注入,在 RMSNorm 实例化的时候就整个实例化为 vllm-ascend 里的类了,并且作为 DeepseekV2Attention 的直接成员存在。
- 后者走的是 quant_config 注入,然后在 layer 实例化时作为 layer 成员存在,也就是说作为 DeepseekV2Attention 的成员的成员存在。
为什么会有这样的两套路径呢?跟 GPT 聊了聊,大概的理解是:
- 有些 layer 是侧重计算的算子型 layer,不涉及大权重矩阵和大权重层量化,比如 kv_a_layernorm,里面压根都没有 quant_method 成员,要换也只能整体替换掉整个 layer。
- 有些 layer 是权重型 layer,checkpoint 里可能已经是量化权重,需要 creat_weights、process_weights_after_loading、apply,不同的量化格式还需要不同的执行策略,这种就适合 layer class 专门作为模型层存在,里面挂上一个 quant_method 成员专门负责这个层的权重怎么建、怎么加载、怎么 matmul。这种情况下,如果要改的点刚好只是 quant_method 的职责范围,比如支持 W4A8 之类的,就可以只替换 quant_method。但是如果要替换的逻辑不再这个范围内,比如是要改整个 forward 的逻辑、weight_load 细节之类的,就只能整个换了,
简单说:
- 改“这个模块怎么跑的” --> 走 CustomOp/PluggableLayer 换 layer
- 改“权重怎么创建、加载、计算的” --> 走 quant_config 换 quant_method
- 两者都涉及 --> 两个都换
- 内部没有扩展点(比如如果存在某个layer,涉及量化权重定制但是却没有 quant_method 成员)--> 只能 layer 整体替换了(或者 patch 应该也行)
PS:无意发现 v0.13 的 vLLM 源码里 ColumnParallelLinear 是个 CustomOp,而 v0.19 里变成 PluggableLayer 了。这里顺手简单记下区别:
两者的存在都是可以支持「换类」,但是 PluggableLayer 相比 CustomOp 更纯粹一点,不涉及根据 platform 做 forward 分发的工作,子类自己实现 forward 就行。而 CustomOp 则实现了一份 forward,内部根据 platform 去调度不同的 forward_xx 方法,例如 NPUPlatform,就会调 forward_oot。
- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝